
Generative pre-trained transformer (GPT)
M.Sc course, University of Debrecen, Department of Data Science and Visualization, 2024
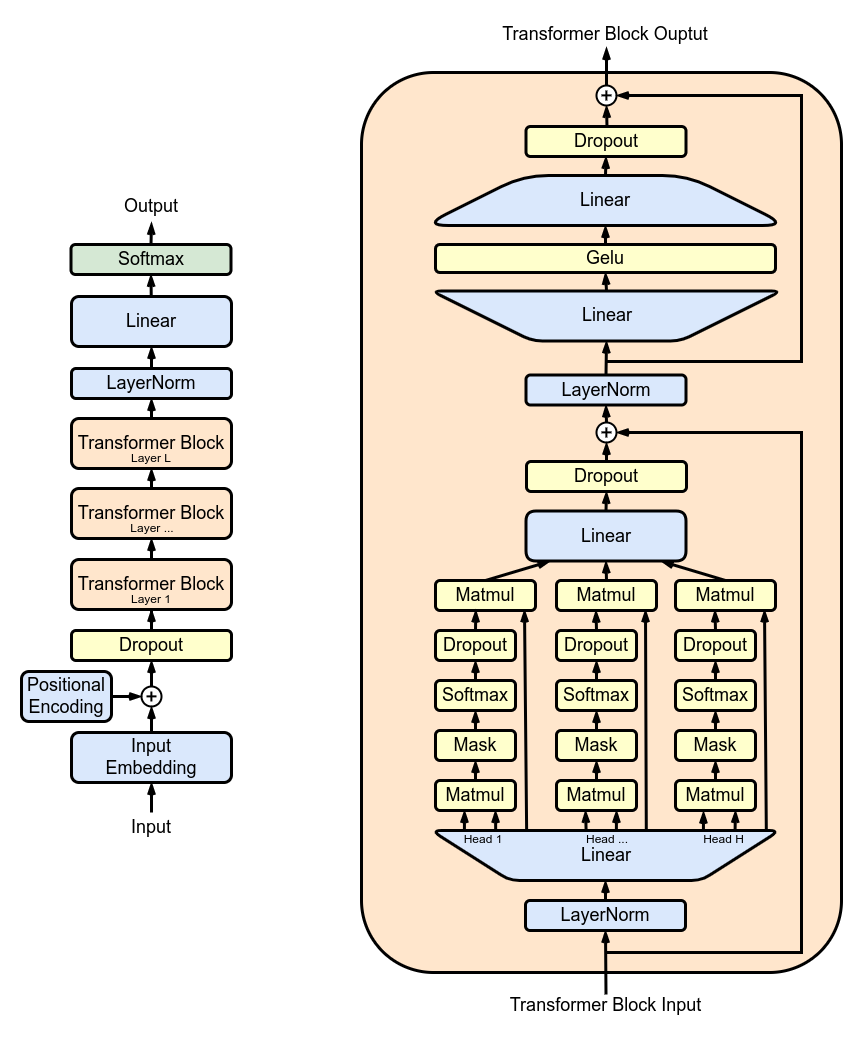
Ábra 1: Transformer architektúra. Forrás: wikipedia.
{kind=link}
Size of GPT
| Model | Architecture | Parameter count | Training data | Release date | Training cost |
|---|---|---|---|---|---|
| GPT-1 | 12-level, 12-headed Transformer decoder (no encoder), followed by linear-softmax. | 117 million | BookCorpus: 4.5 GB of text, from 7000 unpublished books of various genres. | June 11, 2018 | 30 days on 8 P600 GPUs, or 1 petaFLOP/s-day. |
| GPT-2 | GPT-1, but with modified normalization | 1.5 billion | WebText: 40 GB of text, 8 million documents, from 45 million webpages upvoted on Reddit. | February 14, 2019 (initial/limited version) and November 5, 2019 (full version) | “tens of petaflop/s-day”, or 1.5e21 FLOP. |
| GPT-3 | GPT-2, but with modification to allow larger scaling | 175 billion | 499 Billion tokens consisting of CommonCrawl (570 GB), WebText, English Wikipedia, and two books corpora (Books1 and Books2). | May 28, 2020 | 3640 petaflop/s-day, or 3.1e23 FLOP. |
| GPT-3.5 | Undisclosed | 175 billion | Undisclosed | March 15, 2022 | Undisclosed |
| GPT-4 | Also trained with both text prediction and RLHF; accepts both text and images as input. Further details are not public. | Undisclosed. Estimated 1.7 trillion | Undisclosed | March 14, 2023 | Undisclosed. Estimated 2.1e25 FLOP. |
Size of Human Brain
- 86 milliárd neuron van az agyban.
- Minden neuronnak átlagosan körülbelül 7000 szinaptikus kapcsolata van más neuronokkal. Ez a szinapszisok számát 600 milliárd környékére teszi. Kisgyermekeknél a szinaptikus metszés komoly megkezdése előtt a becsült szám eléri az 1 kvadrilliót.
Keras sample
Ez a példa bemutatja, hogyan valósíthat meg egy autoregresszív nyelvi modellt a GPT-modell miniatűr változatával. A modell egyetlen Transformer blokkból áll, amelynek figyelemrétegében oksági maszkolás található. Az IMDB hangulatosztályozási adatkészletének szövegét használjuk a képzéshez, és új filmkritikákat generálunk egy adott prompthoz. Ha ezt a szkriptet saját adatkészletével használja, győződjön meg arról, hogy legalább 1 millió szóból áll.
import os
import string
import random
import numpy as np
import tensorflow as tf
from tensorflow import keras
from tensorflow.keras import layers
from tensorflow.keras.layers import TextVectorization
def causal_attention_mask(batch_size, n_dest, n_src, dtype):
"""
Mask the top half of the dot product matrix to self.
This prevents the flow of information from future tokens to the current token.
1 in the lower triangle, counting from the lower right corner.
"""
i = tf.range(n_dest)[:, None]
j = tf.range(n_src)
m = i >= j - n_src + n_dest
mask = tf.cast(m, dtype)
mask = tf.reshape(mask, [1, n_dest, n_src])
mult = tf.concat(
[tf.expand_dims(batch_size, -1), tf.constant([1, 1], dtype=tf.int32)], 0
)
return tf.tile(mask, mult)
class TransformerBlock(layers.Layer):
def __init__(self, embed_dim, num_heads, ff_dim, rate=0.1):
super().__init__()
self.att = layers.MultiHeadAttention(num_heads, embed_dim)
self.ffn = keras.Sequential(
[layers.Dense(ff_dim, activation="relu"), layers.Dense(embed_dim),]
)
self.layernorm1 = layers.LayerNormalization(epsilon=1e-6)
self.layernorm2 = layers.LayerNormalization(epsilon=1e-6)
self.dropout1 = layers.Dropout(rate)
self.dropout2 = layers.Dropout(rate)
def call(self, inputs):
input_shape = tf.shape(inputs)
batch_size = input_shape[0]
seq_len = input_shape[1]
causal_mask = causal_attention_mask(batch_size, seq_len, seq_len, tf.bool)
attention_output = self.att(inputs, inputs, attention_mask=causal_mask)
attention_output = self.dropout1(attention_output)
out1 = self.layernorm1(inputs + attention_output)
ffn_output = self.ffn(out1)
ffn_output = self.dropout2(ffn_output)
return self.layernorm2(out1 + ffn_output)
Token and Position Embedding layer
class TokenAndPositionEmbedding(layers.Layer):
def __init__(self, maxlen, vocab_size, embed_dim):
super().__init__()
self.token_emb = layers.Embedding(input_dim=vocab_size, output_dim=embed_dim)
self.pos_emb = layers.Embedding(input_dim=maxlen, output_dim=embed_dim)
def call(self, x):
maxlen = tf.shape(x)[-1]
positions = tf.range(start=0, limit=maxlen, delta=1)
positions = self.pos_emb(positions)
x = self.token_emb(x)
return x + positions
Smal GPT model
vocab_size = 20000 # Only consider the top 20k words
maxlen = 80 # Max sequence size
embed_dim = 256 # Embedding size for each token
num_heads = 2 # Number of attention heads
feed_forward_dim = 256 # Hidden layer size in feed forward network inside transformer
def create_model():
inputs = layers.Input(shape=(maxlen,), dtype=tf.int32)
embedding_layer = TokenAndPositionEmbedding(maxlen, vocab_size, embed_dim)
x = embedding_layer(inputs)
transformer_block = TransformerBlock(embed_dim, num_heads, feed_forward_dim)
x = transformer_block(x)
outputs = layers.Dense(vocab_size)(x)
model = keras.Model(inputs=inputs, outputs=[outputs, x])
loss_fn = tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True)
model.compile(
"adam", loss=[loss_fn, None],
) # No loss and optimization based on word embeddings from transformer block
return model
Data
!curl -O https://ai.stanford.edu/~amaas/data/sentiment/aclImdb_v1.tar.gz
!tar -xf aclImdb_v1.tar.gz
batch_size = 128
# The dataset contains each review in a separate text file
# The text files are present in four different folders
# Create a list all files
filenames = []
directories = [
"aclImdb/train/pos",
"aclImdb/train/neg",
"aclImdb/test/pos",
"aclImdb/test/neg",
]
for dir in directories:
for f in os.listdir(dir):
filenames.append(os.path.join(dir, f))
print(f"{len(filenames)} files")
# Create a dataset from text files
random.shuffle(filenames)
text_ds = tf.data.TextLineDataset(filenames)
text_ds = text_ds.shuffle(buffer_size=256)
text_ds = text_ds.batch(batch_size)
def custom_standardization(input_string):
""" Remove html line-break tags and handle punctuation """
lowercased = tf.strings.lower(input_string)
stripped_html = tf.strings.regex_replace(lowercased, "<br />", " ")
return tf.strings.regex_replace(stripped_html, f"([{string.punctuation}])", r" \1")
# Create a vectorization layer and adapt it to the text
vectorize_layer = TextVectorization(
standardize=custom_standardization,
max_tokens=vocab_size - 1,
output_mode="int",
output_sequence_length=maxlen + 1,
)
vectorize_layer.adapt(text_ds)
vocab = vectorize_layer.get_vocabulary() # To get words back from token indices
def prepare_lm_inputs_labels(text):
"""
Shift word sequences by 1 position so that the target for position (i) is
word at position (i+1). The model will use all words up till position (i)
to predict the next word.
"""
text = tf.expand_dims(text, -1)
tokenized_sentences = vectorize_layer(text)
x = tokenized_sentences[:, :-1]
y = tokenized_sentences[:, 1:]
return x, y
text_ds = text_ds.map(prepare_lm_inputs_labels)
text_ds = text_ds.prefetch(tf.data.AUTOTUNE)
class TextGenerator(keras.callbacks.Callback):
"""
Visszahívás szöveg generálásához egy betanított modellből.
1. Tápláljon be néhány indítási parancsot a modellbe
2. Adja meg a következő token valószínűségét
3. Minta a következő tokenből, és adja hozzá a következő bemenethez
Érvek:
max_tokens: Integer, a prompt után generálandó tokenek száma.
start_tokens: Egész számok listája, a kezdő prompt token indexei.
index_to_word: A szövegvektorozási rétegből nyert karakterláncok listája.
top_k: Egész szám, minta a "top_k" token előrejelzéseiből.
print_every: Integer, nyomtatás ennyi korszak után.
"""
def __init__(
self, max_tokens, start_tokens, index_to_word, top_k=10, print_every=1
):
self.max_tokens = max_tokens
self.start_tokens = start_tokens
self.index_to_word = index_to_word
self.print_every = print_every
self.k = top_k
def sample_from(self, logits):
logits, indices = tf.math.top_k(logits, k=self.k, sorted=True)
indices = np.asarray(indices).astype("int32")
preds = keras.activations.softmax(tf.expand_dims(logits, 0))[0]
preds = np.asarray(preds).astype("float32")
return np.random.choice(indices, p=preds)
def detokenize(self, number):
return self.index_to_word[number]
def on_epoch_end(self, epoch, logs=None):
start_tokens = [_ for _ in self.start_tokens]
if (epoch + 1) % self.print_every != 0:
return
num_tokens_generated = 0
tokens_generated = []
while num_tokens_generated <= self.max_tokens:
pad_len = maxlen - len(start_tokens)
sample_index = len(start_tokens) - 1
if pad_len < 0:
x = start_tokens[:maxlen]
sample_index = maxlen - 1
elif pad_len > 0:
x = start_tokens + [0] * pad_len
else:
x = start_tokens
x = np.array([x])
y, _ = self.model.predict(x)
sample_token = self.sample_from(y[0][sample_index])
tokens_generated.append(sample_token)
start_tokens.append(sample_token)
num_tokens_generated = len(tokens_generated)
txt = " ".join(
[self.detokenize(_) for _ in self.start_tokens + tokens_generated]
)
print(f"generated text:\n{txt}\n")
# Tokenize starting prompt
word_to_index = {}
for index, word in enumerate(vocab):
word_to_index[word] = index
start_prompt = "this movie is"
start_tokens = [word_to_index.get(_, 1) for _ in start_prompt.split()]
num_tokens_generated = 40
text_gen_callback = TextGenerator(num_tokens_generated, start_tokens, vocab)
Train
model = create_model()
model.fit(text_ds, verbose=2, epochs=25, callbacks=[text_gen_callback])