
Gyakorlat 10.
B.Sc course, University of Debrecen, Department of Data Science and Visualization, 2024
Megerősítéses Tanulás
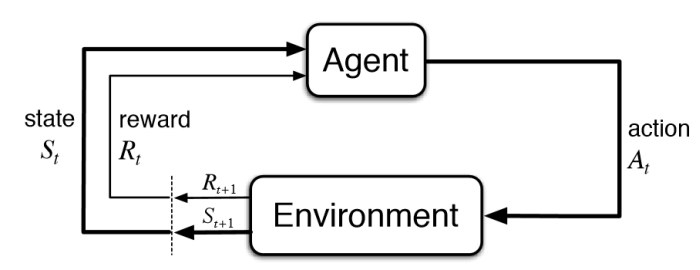
Q-Learning
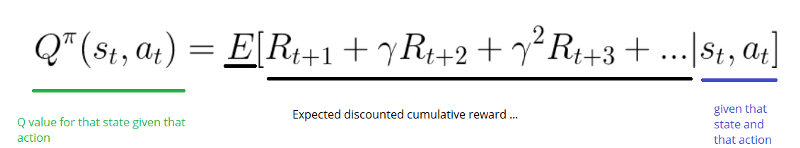
Mi aza Q?
A „q” a q-learningben a minőséget jelenti. A minőség ebben az esetben azt jelenti, hogy egy adott cselekvés mennyire hasznos a jövőbeni jutalom megszerzésében.
Tömören
A Q-learning egy nem szabály alapú megerősítő tanulási algoritmus, amely arra törekszik, hogy megtalálja a jelenlegi állapothoz képest a legjobb lépést. Nem szabály alapú mert véletlenszűrséget használ, ezért nincs szükség szabályokra. Azt is mondthatjuk, hogy a q-learning egy olyan szabály megismerésére törekszik, amely maximalizálja a teljes jutalmat.
Q-tábla
Amikor q-learninget hajtunk végre, létrehozunk egy úgynevezett q-táblát vagy mátrixot, amely követi az [állapot, cselekvés] alakját. Értékeinket nullára inicializáljuk és epizodonként azaz minden egyes művelet után frissitjük. A q-tábla referenciatáblázattá válik ügynökünk számára, hogy a q-érték alapján kiválaszthassa a legjobb műveletet.
import numpy as np
# Initialize q-table values to 0
Q = np.zeros((5, 10))
Q
Frissítések
Az ügynök interakcióba lép a környezettel, és frissíti az állapotműveletpárokat a Q[állapot, művelet] q-táblázatban.
Kiaknázás:
Egy ügynök 2 mód közül egy módon lép kölcsönhatásba a környezettel. Az első az, hogy a q-táblát referenciaként használjuk, és megtekintjük az összes lehetséges műveletet egy adott állapothoz. Az ügynök ezután kiválasztja a legjobb műveletet a műveletek maximális értéke alapján. Ezt kiaknázásnak nevezzük, mivel a rendelkezésünkre álló információkat használjuk fel a döntés meghozatalához.
Felfedezés:
A cselekvés második módja a véletlenszerű cselekvés. Ezt nevezzük felfedezésnek. Ahelyett, hogy a jövőbeni maximális jutalom alapján választanánk ki a cselekvéseket, véletlenszerűen választunk ki egy akciót. A véletlenszerű cselekvés azért fontos, mert lehetővé teszi az ügynök számára, hogy olyan új állapotokat tárjon fel és fedezzen fel, amelyeket egyébként nem választhat ki a kiaknázási folyamat során.
Epsilon:
Az epsilon (ε) használatával egyensúlyba hozhatjuk a felfedezést/kiaknázást, és beállíthajtuk a felfedezés és a kiaknázás gyakoriságát.
Gamma:
A gamma vagy γ diszkonttényező. Az azonnali és a jövőbeli jutalom egyensúlyára szolgál. A kedvezményt a jövőbeni jutalomra alkalmazzuk.
Jutalom:
Az az érték, amelyet egy adott művelet végrehajtása után kapunk egy adott állapotban. A jutalom megtörténhet bármely adott időpontban, vagy csak a végső lépésben.
Max:
A jövőbeli jutalom maximumát veszi fel, és alkalmazza azt a jelenlegi állapot jutalmára. Ez hatással van a jelenlegi cselekvésre a lehetséges jövőbeli jutalommal. Ez a q-learning szépsége. A jövőbeli jutalmat a jelenlegi műveletekhez osztjuk ki, hogy segítsünk az ügynöknek kiválasztani a legmagasabb visszaküldési műveletet bármely adott állapotban.
Tanulási sebesség (lr):
Gyakran alfa-nak vagy α-nak neveznek, egyszerűen úgy definiálható, hogy mennyire fogadja el az új értéket a régi értékhez képest. A fentiekben figyelembe vesszük az új és a régi közötti különbséget, majd ezt az értéket megszorozzuk a tanulási sebességgel. Ezt az értéket ezután hozzáadjuk az előző q-értékünkhöz, ami lényegében a legújabb frissítésünk irányába mozdul.
Cél (terminális) álapot
Az utolsó állapot. Mindig a feladattol függ. A cél teljesítésének végére az algoritmus meghatározza az optimális “q” értéket a (Q*)-ot
Alogritmus
- Az ügynök alap állapotból indul (s1), akciót hajt végre (a1) és jutalmat kap (r1)
- Az ügynök kiválasztja a műveletet a legmagasabb értékű (max) Q-táblázatra való hivatkozással VAGY véletlenszerűen (epsilon, ε)
- Frissítse a q-értékeket
Pong (pong.py)
Hozzunk létre egy pong.py-fájlt
import pygame
import numpy as np
from tqdm import tqdm
# Globális Paraméterek
# Színek
BLACK = (0,0,0)
WHITE = (255,255,255)
RED = (255,0,0)
GREEN = (0,255,0)
BLUE = (0,0,255)
# Jelek a játék dekódolásához
# - üres (egy labdához vagy játékoshoz nem tartozó cella)
SIGN_EMPTY = " "
# - labda
SIGN_BALL = "o"
# - játékos (a téglalap)
SIGN_PLAYER = "x"
# Az "ablak" nagy ítás nélküli mérete
SPACE_SIZE = (20, 20)
# Ezt a felhasználói felület ablakának felnagyítására fogjuk használni
# A felhasználói felület ablakának mérete SPACE_SIZE * ZOOM_SIZE
ZOOM_SIZE = 10
# 3 műveletünk van, amelyeket az ügynök bármikor megtehet:
# - üresjárat (nem változik a helyzet)
ACTION_IDLE = "IDLE"
# - bal
ACTION_LEFT = "LEFT"
# - jobb
ACTION_RIGHT = "RIGHT"
ACTIONS = [
ACTION_IDLE,
ACTION_LEFT,
ACTION_RIGHT
]
# A lapát kezdő koordinátái
rect_x = SPACE_SIZE[0] // 2
rect_y = SPACE_SIZE[1] - 1
# A lapát kezdeti sebessége
rect_change_x = 0
rect_change_y = 0
rect_size_x = 5
rect_size_to_sides_x = rect_size_x // 2
rect_size_y = 1
# A labda kezdeti helyzete
ball_x = SPACE_SIZE[0] // 2
ball_y = 1
# A labda sebessége
ball_change_x = 1
ball_change_y = 1
ball_size_to_sides = 1
# A dictionary-t arra fogjuk használni,
# hogy nyomon követhessük azokat az állapotokat,
# amelyekkel eddig találkoztunk
state_to_id = {}
# A lehetséges állapotok száma összesen
num_states = SPACE_SIZE[0] * SPACE_SIZE[1] * SPACE_SIZE[0] * SPACE_SIZE[1] * 2 * 2
# Képernyő méret
screen = 0
# Agent
agent = None
RED
SIGN_PLAYER
SPACE_SIZE, ZOOM_SIZE
ACTIONS
def drawrect(screen,x,y):
"""Mozgatja a lapátot és korlátozza annak mozgását az ablak szélei között."""
pygame.draw.rect(screen,RED,[(x - rect_size_to_sides_x) * ZOOM_SIZE,y * ZOOM_SIZE, ZOOM_SIZE * rect_size_x, ZOOM_SIZE])
def encode_state(ball_x, ball_y, rect_x, rect_y, ball_change_x, ball_change_y):
"""Kódolja az adott állapotot, hogy megkönnyítse az adott állapot felismerését"""
return (ball_x, ball_y, rect_x, rect_y, ball_change_x, ball_change_y)
def reset():
"""Visszaállítjuk a globális változókat"""
global ball_change_x
global ball_change_y
global ball_size_to_sides
global ball_x
global ball_y
global rect_x
global rect_y
global rect_change_x
global rect_change_y
# A labda mozgásának visszaálítása
ball_change_x = 1
ball_change_y = 1
ball_size_to_sides = 1
# A labda helyzetének visszaállítása
ball_x = SPACE_SIZE[0] // 2
ball_y = 1
# A lapát kezdő koordinátáinak visszaállítása
rect_x = SPACE_SIZE[0] // 2
rect_y = SPACE_SIZE[1] - 1
# A lapát kezdő sebességének visszaállítása
rect_change_x = 0
rect_change_y = 0
def init_pong():
"""Játék inicializálása"""
global screen
global clock
pygame.init()
# A kijelző ablak inicializálása
size = (SPACE_SIZE[0] * ZOOM_SIZE, SPACE_SIZE[1] * ZOOM_SIZE)
screen = pygame.display.set_mode(size)
pygame.display.set_caption("pong")
clock=pygame.time.Clock()
print("Pong init")
def play_episodes(n_episodes=10_000, max_epsilon=1.0, min_epsilon=0.05, decay_rate=0.0001, gamma=0.99, learn=True, viz=False, human=False, log=False):
global ball_change_x
global ball_change_y
global ball_size_to_sides
global ball_x
global ball_y
global rect_x
global rect_y
global rect_change_x
global rect_change_y
global state_to_id
global clock
rewards = []
epsilon_history = []
# Végignézzük az epizódokat
for episode in tqdm(range(n_episodes)):
done = False
# Epszilon csökkentése
epsilon = min_epsilon + (max_epsilon - min_epsilon) * \
np.exp(-decay_rate * episode)
# Környezet visszaállítása
total_reward = 0
reset()
# Első állapot beállítása
state = encode_state(ball_x, ball_y, rect_x, rect_y, ball_change_x, ball_change_y)
if state not in state_to_id:
state_to_id[state] = len(state_to_id)
while not done:
reward = 0
# Háttér színének beállítása
screen.fill(BLACK)
if not human:
# Az Agent-től akciót kérünk, és ennek megfelelően állítjuk be a játékos mozgását
action = agent.act(state=state_to_id[state], epsilon=epsilon)
action_name = ACTIONS[action]
if action_name == ACTION_LEFT:
rect_change_x = -1
elif action_name == ACTION_RIGHT:
rect_change_x = 1
elif action_name == ACTION_IDLE:
rect_change_x = 0
else:
print("Error, unknwon action", action)
exit(-1)
else:
# Emberi inputot is tudunk kezelni
action=0
for event in pygame.event.get():
if event.type == pygame.QUIT:
done = True
elif event.type == pygame.KEYDOWN:
if event.key == pygame.K_LEFT:
rect_change_x = -1
elif event.key == pygame.K_RIGHT:
rect_change_x = 1
elif event.type == pygame.KEYUP:
if event.key == pygame.K_LEFT or event.key == pygame.K_RIGHT:
rect_change_x = 0
elif event.key == pygame.K_UP or event.key == pygame.K_DOWN:
rect_change_y = 0
# Megváltoztatjuk a játékos és a labda helyzetét a végrehajtott akciónak megfelelően.
rect_x += rect_change_x
rect_y += rect_change_y
# Labda mozgsásának kezelése
if ball_x<0:
ball_x=0
ball_change_x = ball_change_x * -1
elif ball_x>SPACE_SIZE[0]:
ball_x=SPACE_SIZE[0]
ball_change_x = ball_change_x * -1
elif ball_y<0:
ball_y=0
ball_change_y = ball_change_y * -1
# Amikor a labda és a játékos ütközik, növeljük a jutalmat és megváltoztatjuk a pályát
elif ball_x + ball_size_to_sides >= rect_x - rect_size_to_sides_x and ball_x - ball_size_to_sides<=rect_x + rect_size_to_sides_x and ball_y==SPACE_SIZE[1]-1:
ball_change_y = ball_change_y * -1
reward = 1
# Akkor fejezzük be az epizódot, amikor a játékos nem találja el a labdát
elif ball_y> SPACE_SIZE[1] - 1:
ball_change_y = ball_change_y * -1
done = True
reward = -1
# Most új állapotba kerültünk, mert megtettünk egy bizonyos intézkedést
new_state = encode_state(ball_x, ball_y, rect_x, rect_y, ball_change_x, ball_change_y)
if new_state not in state_to_id:
state_to_id[new_state] = len(state_to_id)
ball_x += ball_change_x
ball_y += ball_change_y
# Ha az Agent túllép a képernyőn (mindkét oldalon), akkor megszakítjuk az epizódot
if rect_x - rect_size_to_sides_x < 0:
rect_x = 0 + rect_size_to_sides_x
reward = -1
done = True
if rect_x > SPACE_SIZE[0] - rect_size_to_sides_x - 1:
rect_x = SPACE_SIZE[0] - rect_size_to_sides_x - 1
reward = -1
done = True
# Vizualizáljuk a környezetet
if viz:
# Labda
pygame.draw.rect(screen,WHITE,[(ball_x - ball_size_to_sides) * ZOOM_SIZE, (ball_y - ball_size_to_sides) * ZOOM_SIZE, ZOOM_SIZE * ball_size_to_sides, ZOOM_SIZE * ball_size_to_sides])
drawrect(screen,rect_x,rect_y)
pygame.display.flip()
clock.tick(60)
# Frissítjük a Q-table
if learn:
agent.learn(state_to_id[state], action, reward, state_to_id[new_state], gamma)
# A következő időlépés aktuális állapota az aktuális new_state lesz
state = new_state
total_reward += reward
if log:
print("Total reward:", total_reward)
rewards.append(total_reward)
epsilon_history.append(epsilon)
return rewards, epsilon_history
import pong
pong.init_pong()
pong.screen
QLearningAgent (qla.py)
Hozzunk létre egy qla.py-fájlt
import random
import numpy as np
# A Q-learning ügynökünket képviselő osztály
class QLearningAgent:
def __init__(self, n_states, n_actions, learning_rate):
self.n_states = n_states
self.n_actions = n_actions
self.learning_rate = learning_rate
self.q_table = np.zeros((n_states, n_actions))
def act(self, state, epsilon):
# Generáljon véletlen számot a [0, 1] intervallumon
random_int = random.uniform(0,1)
# We exploit with (1-epsilon) probability
if random_int > epsilon:
action = np.argmax(self.q_table[state])
# We explore with epsilon probability
else:
action = random.randint(0, self.n_actions - 1)
return action
def learn(self, state, action, reward, new_state, gamma):
old_value = self.q_table[state][action]
new_estimate = reward + gamma * max(self.q_table[new_state])
self.q_table[state][action] = old_value + self.learning_rate * (new_estimate- old_value)
from qla import QLearningAgent
pong.agent = QLearningAgent(n_states=pong.num_states, n_actions=3, learning_rate=1.0)
pong.agent
# A játék fő köre
clock = pong.pygame.time.Clock()
rewards, epsilon_history = pong.play_episodes(
# n_episodes=50_000,
n_episodes=100,
max_epsilon=1.0,
min_epsilon=0.05,
decay_rate=0.0001,
gamma=0.95,
learn=True,
viz=False,
human=False,
log=False
)
import matplotlib.pyplot as plt
# Ellenőrizhetjük az ügynök teljesítményének történetét
plt.plot(epsilon_history)
plt.show()
plt.plot(rewards)
plt.show()
import pickle
with open("agent.pkl", "wb") as f:
pickle.dump(pong.agent, f)
with open("state_to_id.pkl", "wb") as f:
pickle.dump(pong.state_to_id, f)
Tesztelés
Hozzunk létre egy test.py-fájlt
import libs.pong as pong
import matplotlib.pyplot as plt
pong.init_pong()
import pickle
with open("agent.pkl", "rb") as f:
pong.agent = pickle.load(f)
with open("state_to_id.pkl", "rb") as f:
pong.state_to_id = pickle.load(f)
# Most megfigyelhetjük, hogyan teljesít képzett Agent
rewards, epsilon_history = pong.play_episodes(10, max_epsilon=0, min_epsilon=0, decay_rate=0, gamma=0, learn=False, viz=True, log=True)
plt.plot(epsilon_history)
plt.show()
plt.plot(rewards)
plt.show()
pong.pygame.quit()