
Tokenization
M.Sc course, University of Debrecen, Department of Data Science and Visualization, 2024
Introduction to Natural Language Processing
Natural language processing is a field of science and engineering focused on the development and study of automatic systems that understand and generate natural (that is, human,) languages.
Humans and language
Human languages are communicative devices enabling the efficient sharing and storage of complex ideas, facts, and intents. As argues, the complexity of communication enabled by language is a uniquely human intelligence among species. As scientists and engineers interested in the creation and study of intelligent systems, human language is to us both a fascinating object of study—after all, it has evolved to be learnable and useful—and a great enabler for interacting with humans even in contexts where other modalities (e.g., vision) are also of interest.
Language and machines
Human children, interacting with a rich multi-modality world and various forms of feedback, acquire language with exceptional sample efficiency (not observing that much language) and compute efficiency (brains are efficient computing machines!) With all the (impressive!) advances in NLP in the last decades, we are still nowhere close to developing learning machines that have a fraction of acquisition ability of children. One fundamental (and still quite open) problem in building language-learning machines is the question of representation; how should we represent language in a computer such that the computer can robustly process and/or generate it? This is where this course focuses on the tools provided by deep learning, a highly effective toolkit for representing both the wild variety of natural language and some of the rules and structures it sometimes adheres to. Much of this course will be dedicated to this question of representation, and the rest of this note will talk about a basic subquestion: how do we represent words? Before that, though, let’s briefly discuss some of the applications you can hope to build after learning modern NLP techniques.
A few uses of NLP
Natural language processing algorithms are increasingly useful and deployed, but their failures and limitations are still largely opaque and sometimes hard to detect. Here are a few of the major applications; this list is intended to pique your interest, not to be exhaustive:
Machine translation: Perhaps one of the earliest and most successful applications and driving uses of natural language processing, MT systems learn to translate between languages and are ubiquitous in the digital world. Still, failures of these systems for most of the world’s 7000 languages, difficulties in translating long text, and ensuring contextual correctness of translations make this still a fruitful field of research.
Question answering and information retrieval: The concept of “question answering” should seem overly broad—can’t we express any problem as question answering?—but in NLP, question answering has tended to be related to information-seeking questions (“Who is the emir of Abu Dhabi?”, “What is the process by which I can get an intern visa for the United Kingdom?”). Continually broadening the scope of answerable questions, providing provenance for answers, answering questions in an interactive dialogue—this is one of the fastest-evolving research directions.
Summarization and analysis of text: There are myriad reasons to want to understand (1) what people are talking about and (2) what they think about those things. Companies want to do market research, politicians want to know peoples’ opinions, individuals want summaries of complex topics in digestible form. NLP tools can be powerful for both the increase of access to information to the public, as well as surveillance, corporate or governmental. Bear this aspect of “dual use” in mind as you progress and decide what you are building.
Speech(or sign)-to-text: The process of automatic transcription of spoken or signed language (audio or video) to textual representations is a massive and useful application, but one we’ll largely avoid in this course.
In all aspects of NLP, most existing tools work for precious few (usually one, maybe up to 100) of the world’s roughly 7000 languages, and fail disproportionately much on lesser-spoken and/or marginalized dialects, accents, and more. Beyond this, recent successes in building better systems have far outstripped our ability to characterize and audit these systems. Biases encoded in text, from race to gender to religion and more, are reflected and often amplified by NLP systems. With these challenges and considerations in mind, but with the desire to do good science and build trustworthy systems that improve peoples’ lives, let’s take a look at a fascinating first problem in NLP.
Text cleaning
Text cleaning, also known as text preprocessing or text normalization, is the process of transforming raw text data into a clean and structured format suitable for analysis or further processing. It involves removing noise, irrelevant information, and inconsistencies from the text while retaining the essential content. Text cleaning is an essential step in natural language processing (NLP) and text mining tasks to improve the accuracy and effectiveness of subsequent analyses or machine learning models.
Here are some common techniques used in text cleaning:
Removing Special Characters and Punctuation:
Special characters, such as emojis, symbols, and punctuation marks, are often irrelevant for many NLP tasks and can be removed to simplify the text.
Lowercasing:
Converting all text to lowercase helps in standardizing the text and ensures consistency, especially when case sensitivity is not essential for the analysis.
Tokenization:
Breaking down the text into individual words or tokens is a fundamental step in text cleaning. Tokenization makes it easier to analyze and process the text at a granular level.
Removing Stopwords:
Stopwords are common words that frequently occur in a language (e.g., “and”, “the”, “is”) but often carry little meaning and can be removed to reduce noise in the text.
Stemming and Lemmatization:
Stemming and lemmatization are techniques used to reduce words to their base or root form. This helps in standardizing variations of words and reducing the vocabulary size, which can improve the performance of text analysis tasks.
| Stemming | Lemmatization |
| Stemming is a process that stems or removes last few characters from a word, often leading to incorrect meanings and spelling. | Lemmatization considers the context and converts the word to its meaningful base form, which is called Lemma. |
| For instance, stemming the word Caring would return Car. | For instance, lemmatizing the word Caring. would return Care. |
| Stemming is used in case of large dataset where performance is an issue. | Lemmatization is computationally expensive since it involves look-up tables and what not. |
Handling Numerical Data:
Numeric values, such as dates, times, and numerical quantities, may need to be standardized or replaced with placeholders, depending on the specific analysis or modeling task.
Dealing with HTML Tags and URLs:
In text data scraped from web pages, HTML tags, and URLs may need to be removed or replaced with special tokens to prevent them from affecting the analysis.
Spell Checking and Correction:
In some cases, it may be necessary to perform spell-checking and correction to fix typographical errors and improve the accuracy of the text.
Overall
Text cleaning is highly task-dependent, and the specific techniques used may vary depending on the requirements of the analysis or modeling task. However, the overall goal remains the same: to transform raw text data into a clean, consistent, and standardized format suitable for further processing and analysis.
Tokenization
Tokenization is the process of breaking down a stream of text into smaller units, typically words, phrases, symbols, or other meaningful elements known as tokens. In natural language processing (NLP), tokenization is a fundamental preprocessing step that converts raw text into a format suitable for further analysis, such as machine learning algorithms.
Here’s how tokenization works:
- Breaking Text into Tokens: The text is divided into individual tokens based on specific criteria. The most common approach is to split the text by whitespace to create tokens, where each word becomes a token. However, tokenization can be more complex, taking into account punctuation, special characters, or even linguistic rules.
- Handling Special Cases: Tokenization also deals with special cases, such as handling contractions (e.g., “can’t” becomes “can” and “not” as two tokens), hyphenated words, and abbreviations.
- Normalization: Optionally, tokens may be normalized during the tokenization process. This can involve converting all tokens to lowercase, removing diacritics or accents, or stemming (reducing words to their base or root form).
Tokenization is crucial for various NLP tasks, including:
- Text Analysis: Breaking down text into tokens allows for analysis at a granular level, such as counting word frequencies, identifying patterns, or extracting features for machine learning models.
- Information Retrieval: Tokenization enables the indexing and searching of text documents in information retrieval systems. It helps match user queries with relevant documents based on token matches.
- Machine Translation: In machine translation systems, tokenization segments sentences into tokens, making it easier to align corresponding words or phrases in different languages.
- Part-of-Speech Tagging: Tokenization is often a precursor to part-of-speech tagging, where each token is labeled with its corresponding part of speech (e.g., noun, verb, adjective).
Overall, tokenization is a crucial step in NLP that facilitates text processing and analysis by converting raw text into a structured format that can be manipulated and analyzed computationally.
WordLevel
The text is split into tokens based on whitespace or punctuation boundaries, with each token typically representing a single word in the language. Word-level tokenization is one of the most common tokenization techniques in NLP and serves as the basis for various text processing tasks, including language modeling, text classification, and machine translation.
Word-level tokenization has several advantages:
- Interpretability: Since each token represents a single word, the resulting token sequence is human-readable and interpretable, making it easier to understand the text’s content and structure.
- Compatibility: Word-level tokens are compatible with many NLP models and techniques, including traditional machine-learning algorithms.
- Generalization: Word-level tokenization can generalize well across different languages and domains, making it widely applicable in various NLP tasks.
However, word-level tokenization also has limitations:
- Out-of-Vocabulary (OOV) Words: Words that are not present in the vocabulary used for tokenization may be treated as out-of-vocabulary (OOV) words, leading to issues in downstream tasks like language modeling or machine translation.
- Ambiguity: Some words may have multiple meanings or interpretations, leading to ambiguity in tokenization. Contextual information or additional preprocessing steps may be required to disambiguate such cases.
Overall, word-level tokenization is a fundamental preprocessing step in NLP that facilitates the analysis and processing of text data by breaking it down into its constituent words or tokens.
N-Gram
An n-gram is a contiguous sequence of n items (or words) from a given sample of text or speech. These items can be phonemes, syllables, letters, words, or even symbols, depending on the application. The term “n-gram” comes from the field of computational linguistics and probabilistic modeling, where it is extensively used in tasks such as natural language processing, machine translation, and speech recognition.
- Unigram (n=1): In the context of words, a would be a single word, like “apple”.
- Bigram (n=2): A would be a sequence of two consecutive words, such as “red apple”.
- Trigram (n=3): A would be a sequence of three consecutive words, like “the red apple”.
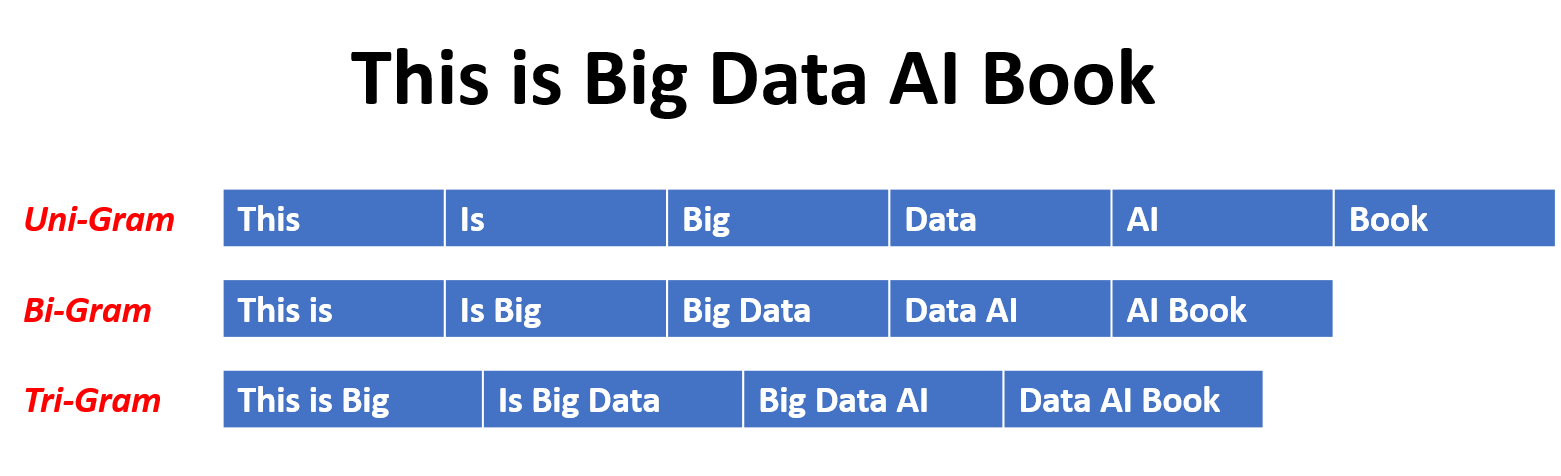
N-grams are particularly useful for statistical language modeling because they capture the likelihood of occurrence of a sequence of words in a language. They are also used in various algorithms for tasks such as text prediction, spell-checking, and sentiment analysis. The choice of the appropriate size of n depends on the specific task and the characteristics of the data being analyzed.
Byte-Pair Encoding (BPE)
Byte-Pair Encoding (BPE) is a data compression algorithm and a technique used in natural language processing (NLP) and text processing for subword tokenization. It was originally introduced as a compression algorithm for efficiently encoding large datasets, but it has gained popularity in NLP for tasks such as machine translation, text generation, and language modeling.
Here’s how Byte-Pair Encoding works in the context of text processing:
- Initialization: Initially, each character or symbol in the text is treated as a token.
- Iterative Merging: BPE iteratively merges the most frequent pair of consecutive tokens (bytes or characters) into a new token. The frequency of token pairs is typically measured based on the frequency of their occurrences in the training corpus.
- Building Vocabulary: As tokens are merged, a vocabulary of subword units is built, where each subword unit represents a sequence of characters. The merging process continues until a predefined vocabulary size is reached or until a certain number of iterations are completed.
Byte-Pair Encoding has several advantages in NLP:
- Flexibility: BPE can capture morphological variations and handle rare or out-of-vocabulary words effectively by breaking them down into smaller subword units.
- Efficiency: BPE can compress text effectively by representing words as sequences of subword units, leading to reduced vocabulary size and improved efficiency in storage and computation.
- Language Agnosticism: BPE is language-agnostic and can be applied to text data in any language without requiring language-specific preprocessing or tokenization rules.
BPE has been widely adopted in various NLP applications and has become a standard technique for subword tokenization in many state-of-the-art NLP models, including neural machine translation models like Google’s Transformer and OpenAI’s GPT (Generative Pre-trained Transformer) models.
Byte-level BPE
Byte-level encoding operates at the character level, where each byte (character) in the text is treated as a token.
Method:
- Each byte of the input text is represented as a token, typically using numerical values corresponding to the byte’s ASCII or Unicode representation.
- Result: The result is a tokenization where each character in the text is represented as a separate token, without any decomposition into subword units.
Example: For example, the word “running” would be tokenized into individual characters “r”, “u”, “n”, “n”, “i”, “n”, “g”.
WordPiece
WordPiece tokenization is a subword tokenization technique used in natural language processing (NLP) to split words into smaller units called subword tokens. It was introduced as part of the BERT (Bidirectional Encoder Representations from Transformers) model developed by Google Research.
WordPiece tokenization iteratively merges the most frequent pair of consecutive tokens (characters or subword units) into a new token until a predefined vocabulary size is reached or a certain number of iterations are completed. The merging process is guided by the frequency of token pairs in the training data.
WordPiece tokenization has been widely adopted in various NLP applications, especially in transformer-based models like BERT, where it has demonstrated significant improvements in performance on a wide range of NLP tasks, including question answering, text classification, and language understanding.
Unigram
Unlike word-level tokenization, which treats each word as a separate token, unigram tokenization operates at the character level, where each character in a word is considered a token.
SentencePiece
SentencePiece tokenization is a subword tokenization technique. It was developed by Google Research as part of the SentencePiece library and has been widely adopted in various NLP applications, particularly in the context of neural machine translation and other sequence-to-sequence tasks.
Here’s how SentencePiece tokenization works:
- Initialization: SentencePiece tokenization starts with an initialization step where each character or byte in the vocabulary is considered as a token. This initial vocabulary may contain individual characters, byte-pair characters, or other subword units.
- Training: SentencePiece tokenization uses unsupervised learning techniques to iteratively refine the vocabulary and segmentation model based on the training data. It employs methods such as byte-pair encoding (BPE) or unigram language model to merge or split subword units, with the goal of maximizing the likelihood of the training data.
- Subword Tokenization: Once the vocabulary and segmentation model are trained, the text is tokenized into subword units based on the learned vocabulary. Unlike traditional word-based tokenization, SentencePiece tokenization allows for representing words as sequences of subword units, capturing morphological variations, rare words, and out-of-vocabulary words more effectively.
- Sentence Boundary Preservation: One of the key features of SentencePiece tokenization is its focus on preserving sentence boundaries. This means that the segmentation model is trained in a way that minimizes the disruption of natural sentence boundaries, ensuring that each subword token corresponds to a coherent linguistic unit within a sentence.
SentencePiece tokenization has several advantages:
- Flexibility: SentencePiece tokenization can capture morphological variations and handle out-of-vocabulary words effectively by breaking them down into smaller subword units.
- Sentence Boundary Preservation: By preserving sentence boundaries, SentencePiece tokenization maintains the coherence and integrity of sentences, which is particularly important for tasks like machine translation and text generation.
- Efficiency: SentencePiece tokenization can achieve efficient representation of text by using a compact vocabulary of subword units, leading to reduced vocabulary size and improved efficiency in storage and computation.
Overall, SentencePiece tokenization is a powerful technique for subword tokenization in NLP, offering flexibility, efficiency, and sentence boundary preservation. It has become a standard approach in many state-of-the-art NLP models, including transformer-based models like BERT and GPT.