
Vectorization
B.Sc course, University of Debrecen, Department of Data Science and Visualization, 2024
Vectorization
Magyar:
Az NLP (Natural Language Processing) területén a vektorizáció az egyik alapvető lépés, amely során a nyelvi adatokat numerikus formába alakítjuk, hogy algoritmusok számára feldolgozhatóvá váljanak.
English:
In the field of NLP (Natural Language Processing), vectorization is one of the basic steps in which language data is converted into numerical form so that it can be processed by algorithms.
corpus = [
"The cat is sitting on the table.",
"There is a dog lying by the table.",
"The dog and the cat are friends, however the dog likes the cat better than the cat likes the dog.",
]
Indexing
import nltk
from nltk.tokenize import word_tokenize
nltk.download('punkt')
words = word_tokenize(" ".join(corpus[:2]).lower())
words = list(set(words))
vocab = {}
for i, word in enumerate(words):
vocab[word] = i
print("Vocab:", vocab)
One-hot Encoding
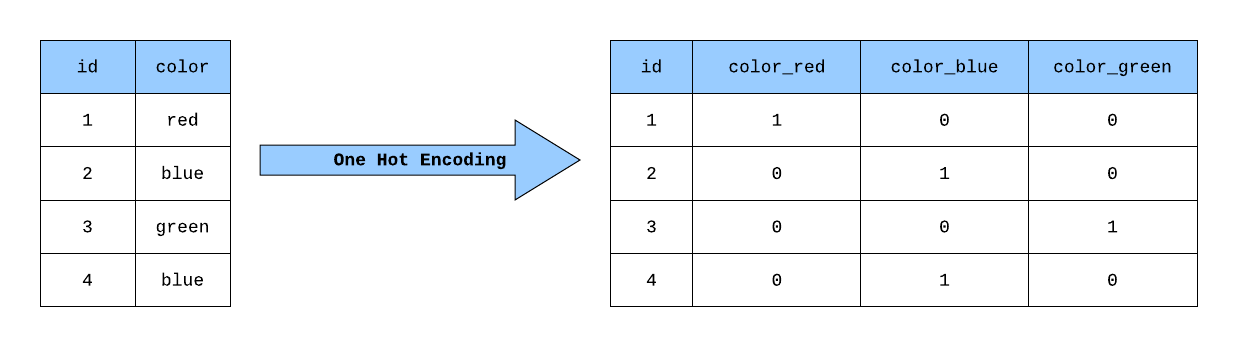
from sklearn.preprocessing import LabelBinarizer
words = word_tokenize(" ".join(corpus[:2]).lower())
words = list(set(words))
lb = LabelBinarizer()
one_hot = lb.fit_transform(list(words))
print("Classes:", lb.classes_)
print("Words:", list(words))
print("One-hot vectors:\n", one_hot)
Count Vectorization / Bag of Words (BoW)
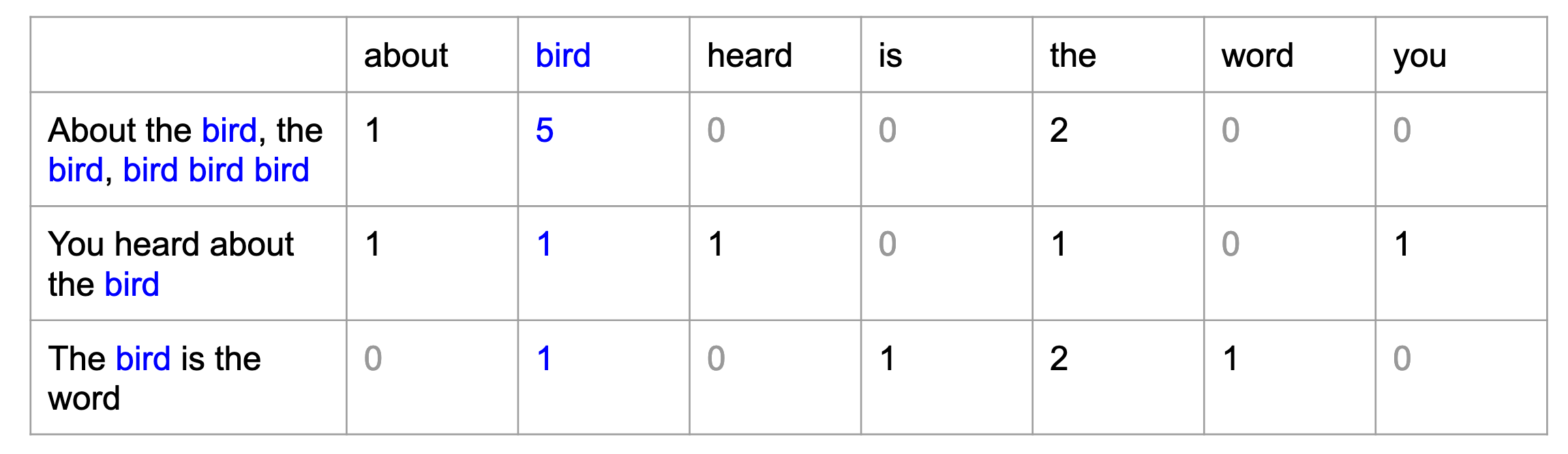
from sklearn.feature_extraction.text import CountVectorizer
corpus_lower = [c.lower() for c in corpus]
count_vect = CountVectorizer()
X_count = count_vect.fit_transform(corpus_lower)
print("Vocab:", count_vect.vocabulary_)
print("Corpus:", corpus_lower)
print("Count vectorization:\n", X_count.toarray())
TF-IDF
Magyar:
TF (Term Frequency): Egy adott szó előfordulása a dokumentumban, normalizálva a dokumentum összes szavához képest.
IDF (Inverse Document Frequency): Annak a mértéke, hogy egy szó mennyire ritka az egész korpuszban. Ez a korpuszban szereplő dokumentumok számának és azoknak a dokumentumoknak a számának aránya, amelyekben a szó szerepel.
English:
TF (Term Frequency): Occurrence of a specific word in the document, normalized to all words in the document.
IDF (Inverse Document Frequency): A measure of how rare a word is in the entire corpus. It is the ratio of the number of documents in the corpus to the number of documents in which the word appears.
Term Frequency (TF)
Magyar:
- n = Az összes szószáma a dokumentumban
- td = Az adott szó előfordulásainak száma a dokumentumban
- TF(t,d) = n / td
English:
- n = Total number of words in the document
- td = Number of occurrences of the given word in the document
- TF(t,d) = n / td
from sklearn.feature_extraction.text import TfidfTransformer
tf_transformer = TfidfTransformer(use_idf=False, norm='l1')
X_tf = tf_transformer.fit_transform(X_count)
print("Term Frequency (TF):\n", X_tf.toarray())
Inverse Document Frequency (IDF)
Magyar:
- D = Összes dokumentum száma.
- d = Azoknak a dokumentumoknak a száma amelyek tartalmazzák az adott szót.
- IDF(t) = log(D)
English:
- D = Number of all documents.
- d = The number of documents that contain the given word.
- IDF(t) = log(D)
tfidf_transformer = TfidfTransformer()
X_tfidf = tfidf_transformer.fit_transform(X_count)
print("IDF értékek:", tfidf_transformer.idf_)
TF-IDF
TD-IDF = TF * IDF
X_tfidf = tfidf_transformer.fit_transform(X_count)
print("TF-IDF:\n", X_tfidf.toarray())